io_uring_0101
IO_URING Asynchronous
Asynchronous - 비동기(非同期)
우리는 우리가 사용하는 대부분의 애플리케이션이 클라우드에 존재하는 시대에 살고 있습니다. 사용자가 클라우드 기반 애플리케이션에 연결할 때마다 일반적으로 일종의 웹 프레임워크 위에 작성되는 대부분의 비즈니스 로직이 실행됩니다. 모든 요청은 별도의 프로세스, 별도의 스레드 또는 비동기 프로그램에서 처리되며 여러 요청은 동일한 프로세스에서 처리됩니다. 오늘날 스레드 풀과 비동기식 모델을 기반으로 하는 애플리케이션 프레임워크도 똑같이 인기가 있습니다. 이러한 응용 프로그램은 작업을 완료하는 데 네트워킹 호출과 파일 관련 시스템 호출을 혼합합니다.
📦 Processes - 프로세스
일반적으로 read(2)와 같은 시스템 호출을 호출하면 파일을 읽고 데이터를 사용할 수 있을 때까지 프로그램이 차단됩니다. 이는 일반적으로 매우 빠른 경향이 있으며 일반적으로 프로그램이 차단되고 있다는 사실을 인식하지 못합니다. 그러나 당신은 아마도 당신의 프로그램, 특히 바쁜 컴퓨터에서 다른 프로그램을 초당 수백 번 실행하기 위해 CPU에서 전환되었을 수도 있다는 사실을 깨닫지 못할 것입니다. 시스템 호출이 차단되면 커널 모드에서 실행 중인 시스템 호출이 반환되어 계속 실행될 때마다 프로그램이 차단 해제됩니다. 대부분의 다른 프로그램과 마찬가지로 운영 체제에서 무언가가 필요할 때마다 차단과 차단 해제 주기를 계속합니다. 이 패러다임은 프로그램이 다른 프로그램을 실행하기 위해 선점(preempted)되거나 시스템 호출에 의해 차단될 수 있더라도 이벤트가 논리적 순서에 따라 차례로 발생하기 때문에 이해하기 쉽습니다. 당신의 프로그램이 다른 프로그램을 실행하기 위해 선점된다는 사실을 무시한다면, 이는 당신의 프로그램이 해당 논리를 순서대로 실행하는 것과 같습니다.
📦 Multi-threaded programs - 멀티스레드 프로그램
멀티스레드 프로그램에서 이 정신적(mental) 모델은 매우 잘 추론됩니다. 당신의 프로그램에는 많은 실행 스레드가 있습니다. 이러한 인스턴스는 동일한 논리의 인스턴스(클라이언트 요청을 처리하기 위해 생성된 스레드의 한 인스턴스)일 수도 있고 그렇지 않은 경우(임시 파일을 정리하기 위해 항상 백그라운드에서 실행되는 전용 스레드)일 수도 있습니다. 이러한 개별 스레드는 시스템 호출에 의해 선점(preempted)되거나 차단(blocked)되거나 차단 해제(unblocked)됩니다. 그 중 몇 개 또는 여러 개가 실행되고 있지만 이 정신(mental) 모델도 상당히 확장 가능합니다. 그러나 멀티스레드 여정에서 만나게 될 잠금 및 뮤텍스(mutexes)와 같은 복잡한 내용은 여전히 존재합니다. 그러나 우리의 논의에서는 그것들을 무시하는 것이 가장 편리할 것입니다.
📦 Why asynchronous programming? - 왜 비동기 프로그램인가?
시간당 수천 또는 수십만 개의 요청을 처리하는 무언가를 구축하려는 경우 비동기 I/O에 신경 쓸 필요가 없습니다.
스레드 풀(thread pool) 기반 아키텍처를 중심으로 설계된 애플리케이션 프레임워크는 여러분에게 큰 도움이 될 것입니다.
그러나 시간당 수백만 개의 요청을 효율적으로 처리하고 효율성에 관심이 있다면 비동기 프로그래밍을 더 자세히 살펴보는 것이 좋습니다.
비동기 프로그래밍은 단일 스레드에서 많은 I/O를 처리하여 운영 체제의 스레드/프로세스 컨텍스트 전환 오버헤드를 방지합니다.
운영 체제의 컨텍스트 전환 오버헤드는 별 것 아닌 것처럼 보일 수도 있지만 상당한 규모와 동시성을 처리할 때 문제가 되기 시작합니다.
1초 동안 일련의 요청에서 어떤 일이 발생하는지 설명하는 다음 그림을 고려하세요.
스레드는 차단 상태에서 실행 상태로 전환됩니다.
단일 스레드 및 다중 스레드 앱에서 무슨 일이 일어나는지는 분명하지만, 비동기 프로그래밍이 어떻게 작동하는지 이해하는 것은 약간 까다로울 수 있습니다.
비록 그것이 로켓 과학은 아니지만 말입니다.
아래 그림이 이해에 도움이 되길 바랍니다.
[그림 1] - Single threaded app

[그림 2] - Multi-threaded app
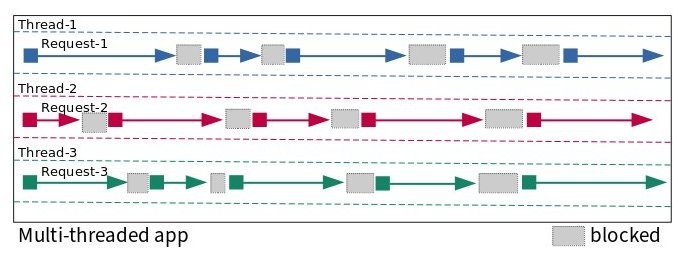
[그림 3] - Asynchronous app; Single threaded
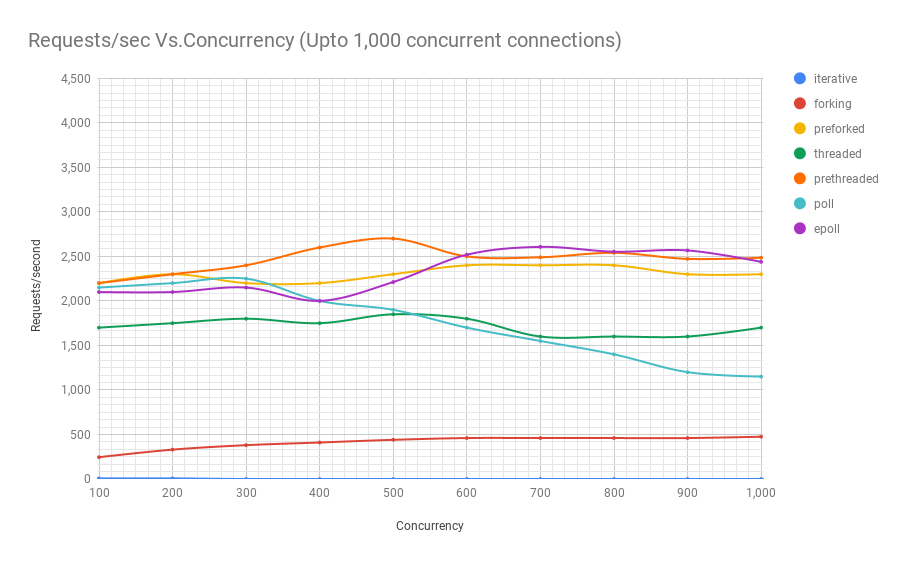
다음은 기능적으로 동일하지만 다른 Linux 프로세스 모델을 사용하여 작성된 교육용 웹 서버를 사용하여 실험을 실행한 차트입니다.
각 아키텍처의 이름에 대한 설명은 다음과 같습니다.
- 반복(Iterative): 이 서버 유형은 요청을 하나씩 처리합니다. 하나의 요청을 처리하는 동안 도착할 수 있는 다른 요청은 이전 요청의 처리가 완료될 때까지 기다려야 합니다. 운영 체제가 대기하는 요청 수에는 제한이 있습니다. 기본적으로 Linux는 5.4 미만 커널 버전의 경우 최대 128개, 최신 커널 버전의 경우 최대 4,096개를 대기열에 추가합니다.
- 프로세스 생성(Forking): 이 유형의 서버는 처리해야 하는 각 요청에 대해 새로운 프로세스를 생성합니다. 이렇게 하면 요청이 이전 요청이 처리될 때까지 기다릴 필요가 없습니다. 서로 다른 프로세스는 서로 다른 요청을 처리합니다. 또한 작동하는 프로세스나 스레드가 많으면 사용 가능한 여러 CPU 코어를 활용하는 경향이 있습니다.
- 프로세스 미리 생성(Preforked): 이 유형의 서버는 요청을 처리해야 할 때마다 완전히 새로운 프로세스를 생성해야 하는 오버헤드를 방지합니다. 요청이 들어올 때 할당되는 프로세스 풀을 생성하여 이를 수행합니다. 풀의 모든 프로세스가 사용 중일 때만 들어오는 요청이 처리될 차례를 기다려야 합니다. 그리고 관리자는 일반적으로 경험하는 로드에 따라 풀의 프로세스 수를 조정할 수 있습니다.
- 스레드(Threaded): 이 유형의 서버는 요청을 처리해야 할 때마다 새 스레드를 생성합니다.
스레드는 스레드를 생성하는 기본 프로세스와 많은 데이터를 공유하므로 새 프로세스를 생성하는 것에 비해 생성 중에
오버헤드가 약간 낮습니다(1).
(1) 오버헤드가 약간 낮은 이유 설명: Linux에서 스레드 또는 프로세스 생성은 둘 다 clone(2) 시스템 호출로 수행되고 동일한 오버헤드가 발생하지만, 생성 직후 부모 주소 공간의 읽기 전용 복사본을 공유하는 자식 프로세스가 해당 페이지에 쓰는 경우, 커널은 자식을 위해 부모 주소 공간의 복사본을 생성하는데, 이는 실제 오버헤드입니다. 프로세스의 스레드는 주소 공간을 공유하므로 이러한 복사 오버헤드가 발생하지 않습니다. - 스레드 미리 생성(Prethreaded): 이것은 프로세스 미리 생성(preforked) 아키텍처와 동등한 스레드입니다. 이 스타일에서는 스레드 풀이 생성되고 풀의 스레드에 요청이 들어올 때 할당됩니다. 사전 포크 모델에서와 마찬가지로 요청은 모든 스레드가 이전에 수신된 요청을 처리하는 중일 경우에만 대기해야 합니다. 이는 매우 효율적인 모델이며 대부분의 웹 애플리케이션 프레임워크가 따르는 모델입니다.
- 반복 확인(Poll): 이 유형의 서버는 단일 스레드이며 poll(2) 시스템 호출을 사용하여 요청 간 다중화를 수행합니다. 그러나 poll(2)은 심각한 제한이 있는 시스템 호출입니다. 즉, 많은 수의 파일 설명자로 확장하면 성능 문제가 있습니다. 아래 차트를 보면 이를 확인할 수 있습니다. 이러한 종류의 설계에서는 각 요청의 상태가 추적되고 해당 요청을 다음 단계로 처리하는 함수에 대한 일련의 콜백이 만들어집니다.
- epoll: 이것은 또한 poll(2) 대신 epoll(7) 시스템 호출 계열을 사용하는 일종의 단일 스레드 서버이지만 그 외에는 구조적으로 동일합니다.
이제 다양한 아키텍처의 이름이 무엇을 의미하는지 알았으므로 특정 동시성에서 처리할 수 있는 초당 요청 수를 살펴보겠습니다.
아래 세 차트는 동일한 벤치마크에서 나온 것이지만 결과를 더 잘 나타내기 위해 결과를 확대한 것입니다.
[차트 1] - Concurrency: Requests/sec Vs. Concurrency (Upto 1,000 concurrency connections)
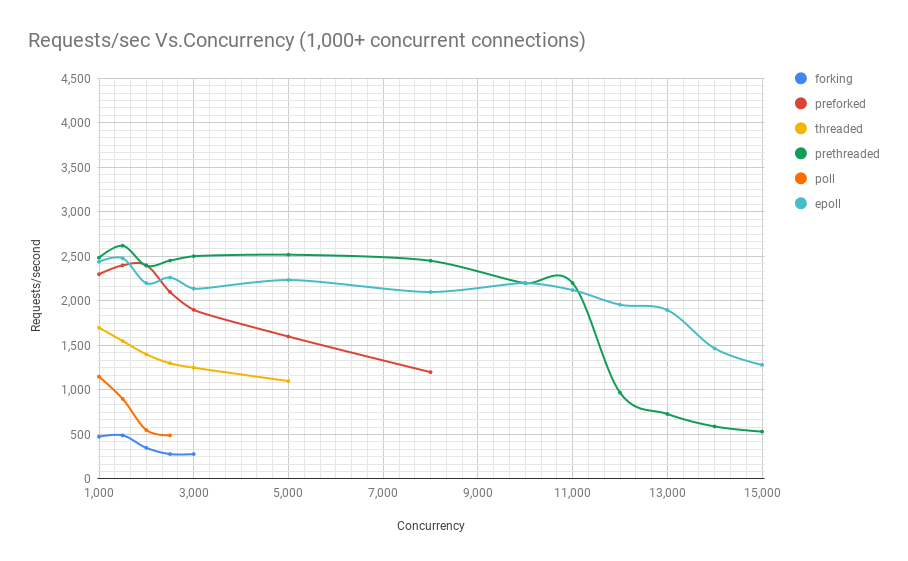
[차트 2] - Concurrency: Requests/sec Vs. Concurrency (1,000+ concurrency connections)
[차트 3] - Concurrency: Requests/sec Vs. Concurrency
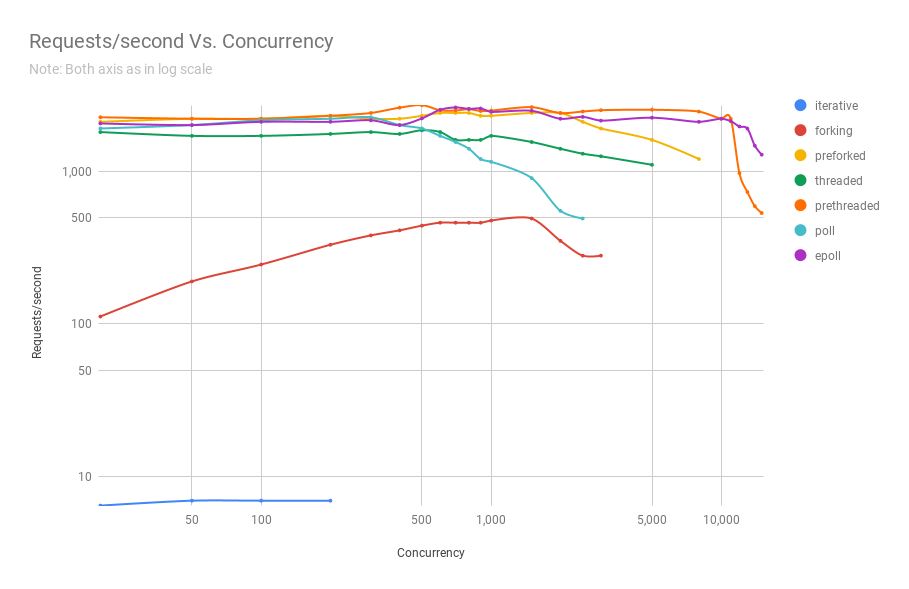
[차트 2]에서 보시다시피, 스레드 미리 생성(prethreaded) 또는 스레드 풀(thread pool) 기반 웹 서버는 epoll(7) 기반 서버가
이 특정 벤치마크에서 최대 11,000명의 사용자가 동시 실행될 때까지 돈을 벌 수 있는 성능을 제공합니다.
그리고 동시접속자가 너무 많네요. 매우 인기 있는 웹 서비스 만 이 이러한 종류의 동시성을 경험합니다.
복잡성 측면에서 스레드 풀 기반 프로그램이 비동기식 프로그램에 비해 코딩하기가 훨씬 쉽다는 점을 고려하면 이는 매우 중요합니다.
이는 또한 본질적으로 이해하기가 훨씬 쉽기 때문에 유지 관리가 훨씬 더 쉽다는 것을 의미합니다.
애플리케이션에서 사용할 수 있는 다양한 Linux 프로세스 모델을 자세히 살펴보는 내 기사 시리즈를 읽어보세요.
이는 다양한 프로세스 아키텍처를 기반으로 기능적으로 동일한 웹 서버를 처음부터 구축함으로써 수행됩니다.
Linux Applications Performance: Introduction
Part I. Iterative Servers
Part II. Forking Servers
Part III. Pre-forking Servers
Part IV. Threaded Servers
Part V. Pre-threaded Servers
Part VI: poll-based server
Part VII: epoll-based server
📦 Making asynchronous programming easier - 비동기 프로그래밍을 더 쉽게 만들기
비동기 아키텍처로 프로그램을 빌드할 때 일반적으로 개발자로서의 삶을 더 쉽게 만들어주는 고급 라이브러리를 사용합니다.
또 다른 선택은 가장 낮은 수준에서 비동기 Linux 인터페이스를 처리하는 방식으로 프로그램을 계층화하고 상위 계층은 기능을 구축하는
더 사용하기 쉬운 인터페이스를 제공하는 것입니다.
이러한 하위 수준 운영 체제 인터페이스를 추상화하는 라이브러리의 좋은 예는 'NodeJS'를 지원하는 'libevent' 및 'libuv'입니다.
⚛ NodeJS는 libevent에서 영감을 얻어 NodeJS 용으로 'libuv'를 만들었습니다.
웹 프레임워크나 고성능 네트워크 서비스와 같은 특수 애플리케이션을 작성하지 않는 한 일반적으로 이러한 하위 수준 API에서
프로그래밍을 처리할 필요가 없습니다.
하지만 궁금하고 시스템 프로그램이 어떻게 작동하는지 이해하고 싶다면 잘 찾아오셨습니다.
이 세상에서는 호기심이 고양이를 죽이지 않습니다. 종종 호랑이로 변합니다.
'Tornado' 및 'NodeJS'와 같은 웹 애플리케이션 프레임워크를 사용하면 비동기 I/O가 제공하는 성능을 활용하여
웹 애플리케이션을 쉽게 작성할 수 있습니다.
웹 서비스 또는 요즘 데스크톱 애플리케이션을 작성하는 경우 이러한 프레임워크를 사용하면 많은 성능 이점을 유지하면서
고급 언어로 비즈니스 논리를 작성할 수 있으므로 이러한 프레임워크를 사용하고 싶을 수 있습니다.
📦 Linux asynchronous APIs before io_uring - io_uring 이전의 Linux 비동기 API
우리는 동기식 프로그래밍을 사용하여 읽기나 쓰기 또는 accept(2)의 경우 원격 연결을 처리하는 시스템 호출이 각각 데이터를 읽거나
쓸 때까지 또는 클라이언트 연결을 사용할 수 있을 때까지 차단한다는 것을 확인했습니다.
그때까지는 해당 프로세스나 스레드가 차단됩니다. 다른 일을 해야 한다면 어떻게 합니까?
스레드를 사용하면 다른 스레드를 생성하여 이러한 다른 작업을 처리할 수 있습니다.
예를 들어, 새 클라이언트 연결이 즉시 처리되도록 accept(2)에서 메인 스레드를 차단하고 다른 스레드는
이전 클라이언트의 요청을 처리할 수 있습니다.
그러나 클라이언트 소켓에서 읽으려고 시도하는 동시에 로컬 파일을 읽거나 쓰려고 시도하면서 동시에 클라이언트 연결을
허용하기 위해 활성 상태를 유지해야 한다면 어떻게 될까요?
파일을 제공(읽기)하고 수락(쓰기)하는 FTP 서버가 소켓과 일반 파일 설명자를 모두 처리하는 것이 좋은 예입니다.
하나의 스레드나 프로세스에서 이를 어떻게 수행합니까? 이것이 select(2), poll(2) 및 epoll(7) 계열의 시스템 호출이 들어오는 곳입니다.
이러한 시스템 호출을 사용하면 여러 파일 설명자(소켓도 파일 설명자임)를 모니터링하고 그 중 하나 이상이 준비되면 알려줄 수 있습니다.
예를 들어 FTP 서버는 새로운 클라이언트 요청에 대해 accept(2)를 수신하면서 연결된 몇몇 클라이언트로부터 다음 명령을 읽기를 기다리고 있습니다.
프로그램은 select(2), poll(2) 또는 epoll(7) 시스템 호출 계열에 이러한 파일 설명자를 모니터링하고
그 중 하나 이상에 활동이 있을 때 프로그램에 알리도록 지시합니다.
이를 위해서는 프로세스나 스레드에서만 각 요청을 처리하는 방식에 비해 프로그램을 매우 다르게 구성해야 합니다.
Linux의 aio(7) 시스템 호출 계열은 파일과 소켓 모두를 비동기적으로 처리할 수 있습니다.
그러나 알아야 할 몇 가지 제한 사항이 있습니다.
- aio(7) O_DIRECT 에서는 버퍼링되지 않은 모드(unbuffered mode)로 열린 파일만 지원됩니다. 이것은 의심할 여지 없이 가장 큰 한계이다. 일반적인 상황에서 모든 응용 프로그램이 버퍼링되지 않은 모드에서 파일을 열고 싶어하는 것은 아닙니다.
- 버퍼링되지 않은 모드에서도 파일 메타데이터를 사용할 수 없으면 aio(7)가 차단될 수 있습니다. 사용할 수 있을 때까지 기다립니다.
- 일부 저장 장치에는 요청을 위한 고정된 개수의 슬롯이 있습니다. 모든 슬롯이 사용 중인 경우 aio(7) 제출(submission)이 차단될 수 있습니다.
- 제출(submission) 및 완료(completion)를 위해 총 104바이트를 복사해야 합니다. 또한 I/O를 위해 이루어져야 하는 두 가지 시스템 호출(제출 및 완료를 위해 각각 하나씩)이 있습니다.
위의 제한으로 인해 aio(7) 하위 시스템 에 많은 불확실성과 성능 오버헤드가 발생합니다 .
📦 The trouble with regular files - 일반 파일의 문제점
사용량이 많지 않은 서버에서는 파일을 읽거나 쓰는 데 시간이 오래 걸리지 않을 수 있습니다.
비동기식 설계를 사용하여 작성된 위의 FTP 서버 예제를 살펴보겠습니다.
동시 접속자가 많아 대용량 파일을 한꺼번에 다운로드하고 업로드하는 등 바쁜 일상을 보낼 때,
프로그래머로서 꼭 알아야 할 고민이 하나 있다.
이렇게 바쁜 서버에서는 read(2) 및 write(2) 호출이 많이 차단될 수 있습니다.
하지만 여기서는 select(2), poll(2) 또는 epoll(7) 시스템 호출 계열이 도움이 되지 않을까요? 불행히도 도움이 되지 않는다.
이러한 시스템 호출은 항상 일반 파일에 I/O 준비가 완료되었음을 알려줍니다.
이것이 그들의 아킬레스 건입니다. 왜 그런지는 자세히 설명하지 않겠지만,
소켓에서는 정말 잘 작동하지만 일반 파일에서는 항상 "준비(ready)"를 반환한다는 점을 이해하는 것이 중요합니다.
불행하게도 이로 인해 비동기 프로그래밍에서는 파일 설명자가 균일하지 않게(non-uniform) 됩니다.
일반 파일을 백업하는 파일 설명자는 차별됩니다.
이러한 이유로 라이브러리는 libuv 일반 파일의 I/O에 별도의 스레드 풀을 사용하여 이러한 불일치를 사용자에게 숨기는 API를 노출합니다.
다양한 운영 체제에서 비동기 I/O API를 조사한 훌륭한 기사를 읽어보세요.
Asynchronous disk I/O (2012)
📦 Does this problem exist in io_uring? - io_uring에 이 문제가 존재합니까?
아니요. 'io_uring'은 소켓을 처리하든 일반 파일을 처리하든 통일된 인터페이스를 제공합니다. 또한 API 설계로 인해 프로그램은 poll(2) 또는 epoll(7)에서와 같이 파일 설명자가 언제 준비되었는지 확인한 다음 나중에 I/O 작업을 시작하는 대신 파일 설명자에서 직접 읽거나 쓰는 데이터를 얻을 수 있습니다. 이것이 'io_uring'이 기존 Linux 비동기 I/O API에 비해 갖는 유일한 장점은 아닙니다. 다음 섹션에서 더 자세히 논의하겠습니다.
⚛ 원문